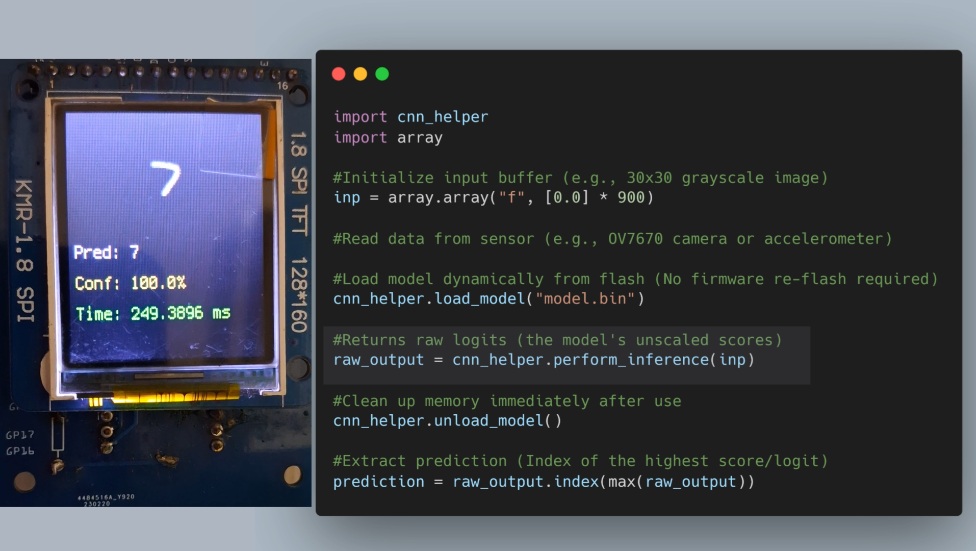
For some time, I’ve been deeply engrossed in the challenge of training a custom model for my Maix Dock M1, a K210 board. This journey hasn’t been without its frustrations, especially due to the lack of comprehensive documentation, which turned out to be a significant hurdle. However, after a lo
...
Read more ...