A typical Natural Language Processing(NLP) pipeline contains many inference tasks by employing models created in different programing languages and frameworks. Today there are many established ways to deploy and scale inference mechanisms based on a single ML model. But scaling a pipeline is not that simple. In this article we will see how we can create a scalable NLP pipeline that can theoretically processes thousands of text messages in parallel using my open source project Nlphose, Kafka and Kubernetes.
Introduction to nlphose
Nlphose enables creation of complex NLP pipelines in seconds, for processing static files or streaming text, using a set of simple command line tools. No programing needed! You can perform multiple operation on text like NER, Sentiment Analysis, Chunking, Language Identification, Q&A, 0-shot Classification and more by executing a single command in the terminal. You can read more about this project here https://github.com/code2k13/nlphose. Nlphose also has a GUI query builder tool that allows you to create complex NLP pipelines via drag and drop, right inside your browser. You can checkout the tool here : https://ashishware.com/static/nlphose.html
Create a nlphose pipeline
Recently I added two components to my project:
- Kafka2json.py - This tool is similar to kafkacat. It can listen to a Kafka topic and stream text data to the rest of the pipeline.
- Kafkasink.py - This tool acts like a ‘sink’ in the NLP pipeline and writes the output of the pipeline to a Kafka topic.
In this article we will use the graphical query builder tool to create a complex NLP pipeline which looks like this :
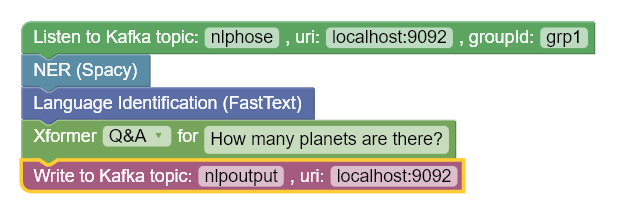
The pipeline does following things:
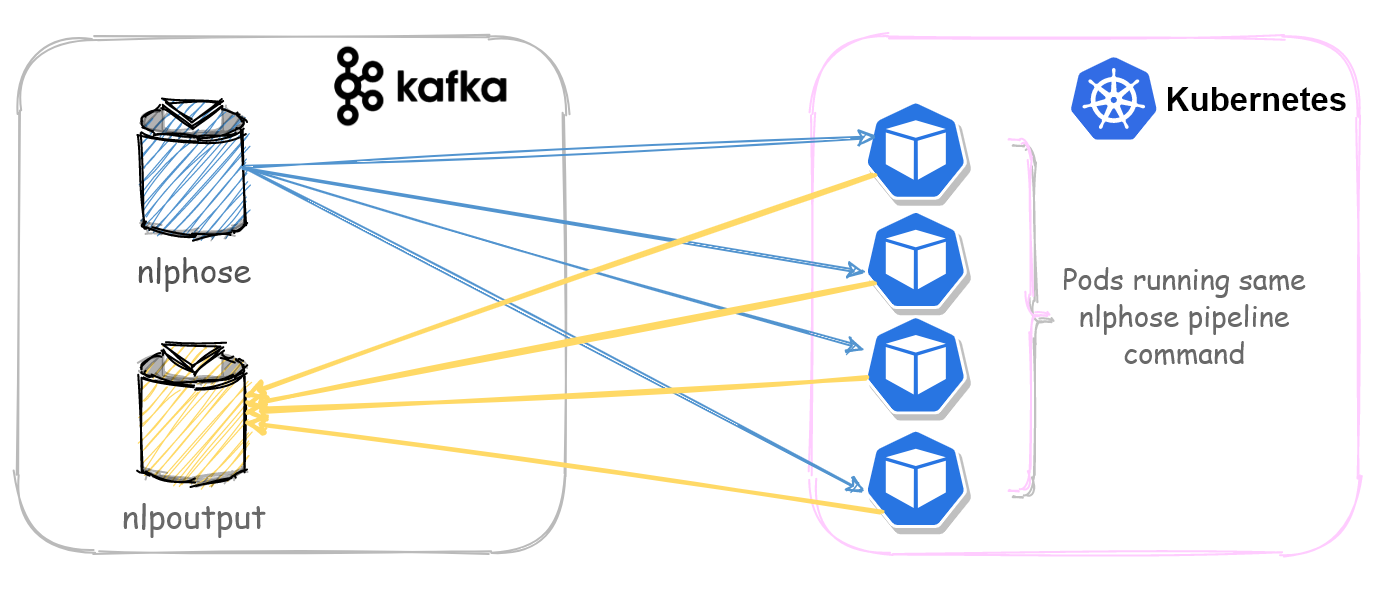
- Listen to a topic called ‘nlphose’ on Kafka
- Named Entity Recognition (automatic geo-tagging of locations)
- Language identification
- Searches for answer of the question “How many planets are there?”, using extractive question answering technique.
- Writes output of the pipeline to a Kafka topic ‘nlpoutput’
This is what the Nlphose command for the above pipeline looks like :
./kafka2json.py -topic nlphose -endpoint localhost:9092 -groupId grp1 |\ |
Configuring Kafka
This article assumes you already have a Kafka instance and have created two topics ‘nlphose’ and ‘nlpoutput’ on it. If you do not have access to a Kafka instance, please refer to this quick start guide to setup Kafka on your development machine. The Kafka instance should be accessible to all the machines or Kubernetes cluster which are running the Nlphose pipeline. In this example, the ‘nlphose’ topic had 16 partitions. We will use multiple consumers in a single group to subscribe to this topic and process messages concurrently.
Deploying the Nlphose pipeline on Kubernetes
Nlphose comes with a docker image containing all the code and models required for it to function. You will simply have to create a deployment in Kubernetes to run this pipeline. Given below is a sample deployment file:
apiVersion: apps/v1 |
Please ensure that you change ‘127.0.0.1:9092’ to correct IP and port of your Kafka instance.
Deploying the Nlphose pipeline without Kubernetes
Kubernetes is not mandatory to create scalable pipelines with Nlphose. As a Nlphose pipeline is just a set of shell commands, you can run these on multiple bare metal machines or VMs or PaaS solutions. When used with Kafka plugins, Nlphose is able to concurrently processes Kafka messages, so long as the same groupId is used on all computers running the pipeline. Simply copy paste output from the GUI query builder and paste it in the terminal of the target machines. You have a cluster of computers executing the pipeline concurrently !
Benchmarking and results
I create a small program that continuously posted below message on Kafka topic ‘nlphose’:
message = { |
The corresponding processed message generated by the pipeline looks like this:
{ |
The below graph shows results from experiments I performed on GKE and a self hosted Kafka instance. It can be clearly seem from the below chart that the time required to process request goes down with addition of more instances.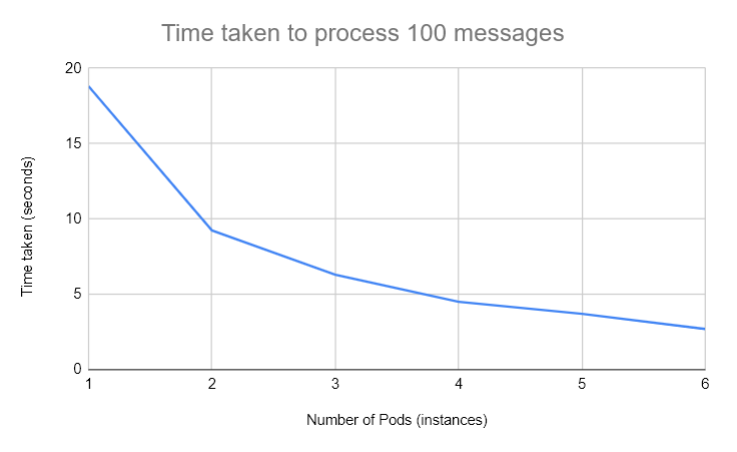
Conclusion
With the addition of new Kafka plugins Nlphose has become a true big data tool. I am continuously working on making it more useful and easy to operate for end users. Nlphose can work with Kubernetes, Docker or bare metal. Also, you can customize or add new tools to these pipelines easily if you stick to the guiding principles of the project. Hope you found this article useful. For any suggestions or comments please reach me on Twitter or Linkedin.



