As a ML practitioner, I am always on a lookout for cheap and easy ways for hosting my model. Google Cloud Functions can be a great option in such cases. In this article I will discuss some advantages of hosting your models for inference using Google Cloud Functions.
Why Serverless / Google Cloud Functions
- Easy to deploy, all you need to do is basically write a function that performs predictions.
- Easy and automatic scalability.
- You get billed only when the function is called (great for hobby projects and demos !)
- Multiple triggers. You can trigger your AI model in multiple ways (not just via REST endpoint). This allows for creating complex AI based pipelines. At the time of writing this article following triggers were available:
- HTTP
- Cloud Storage
- Cloud Pub/Sub
- Cloud Firestore
- Firebase (Realtime Database, Storage, Analytics, Auth)
- Stackdriver Logging
- Detailed performance and usage reports. Most serverless offerings from major cloud providers come with great support for capturing and displaying metrics
around your models performance.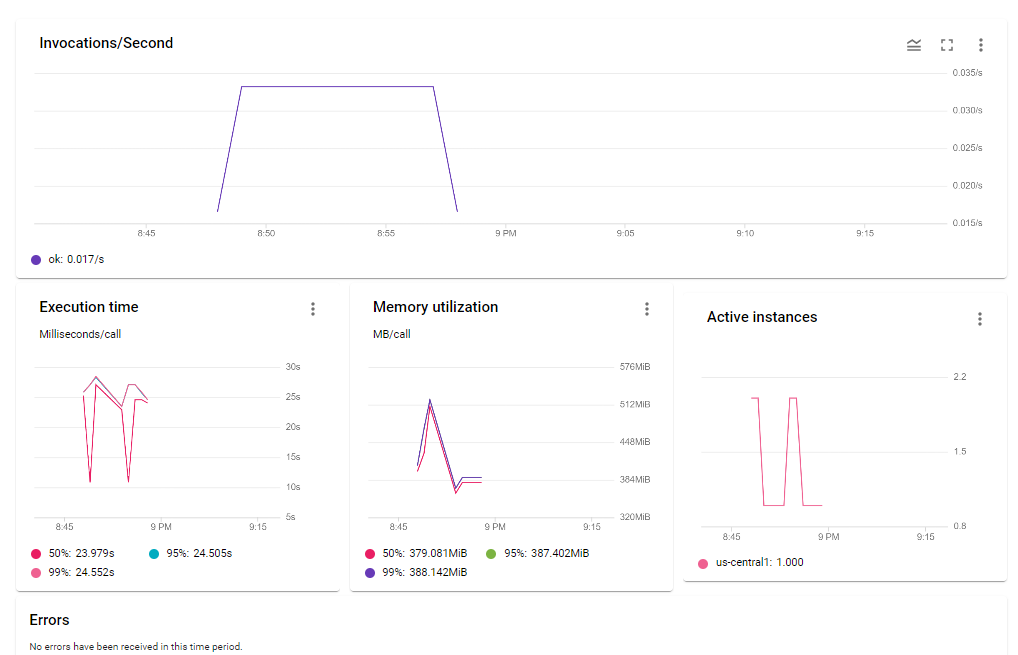
Tips to host your function
Tip 1: Save money by choosing appropriate RAM
To save money you always will want to run your functions at the lowest memory environment possible. If you know the exact amount of memory your code requires, making a choice is simple. If you are not sure, start with a lower memory container and determine the best fit using trial and error.
Tip 2: If possible bundle your model and dependencies with your code
If your model is small you should consider bundling it with the function code, along with any other things that may be required for running the model like weights, vectorizers, dictionaries etc. Though the preferred place to keep this data is a cloud storage bucket, you can save on some precious time by bundling such dependencies with your code.
Tip 3: You can benefit from cold start and using global variables
Basically a serverless function is stateless. That means you end up repeating each and every step required to make predictions every time the function is invoked. Luckily, there is a ‘state’ aspect to cloud functions as mentioned here. What this means is that depending upon the load, multiple calls to a function can be directed to the same instance of the function. In such cases any global variables which have been loaded are preserved and their value is available inside the actual function. These global variables can be used to hold models and results of any task which is computationally expensive.



