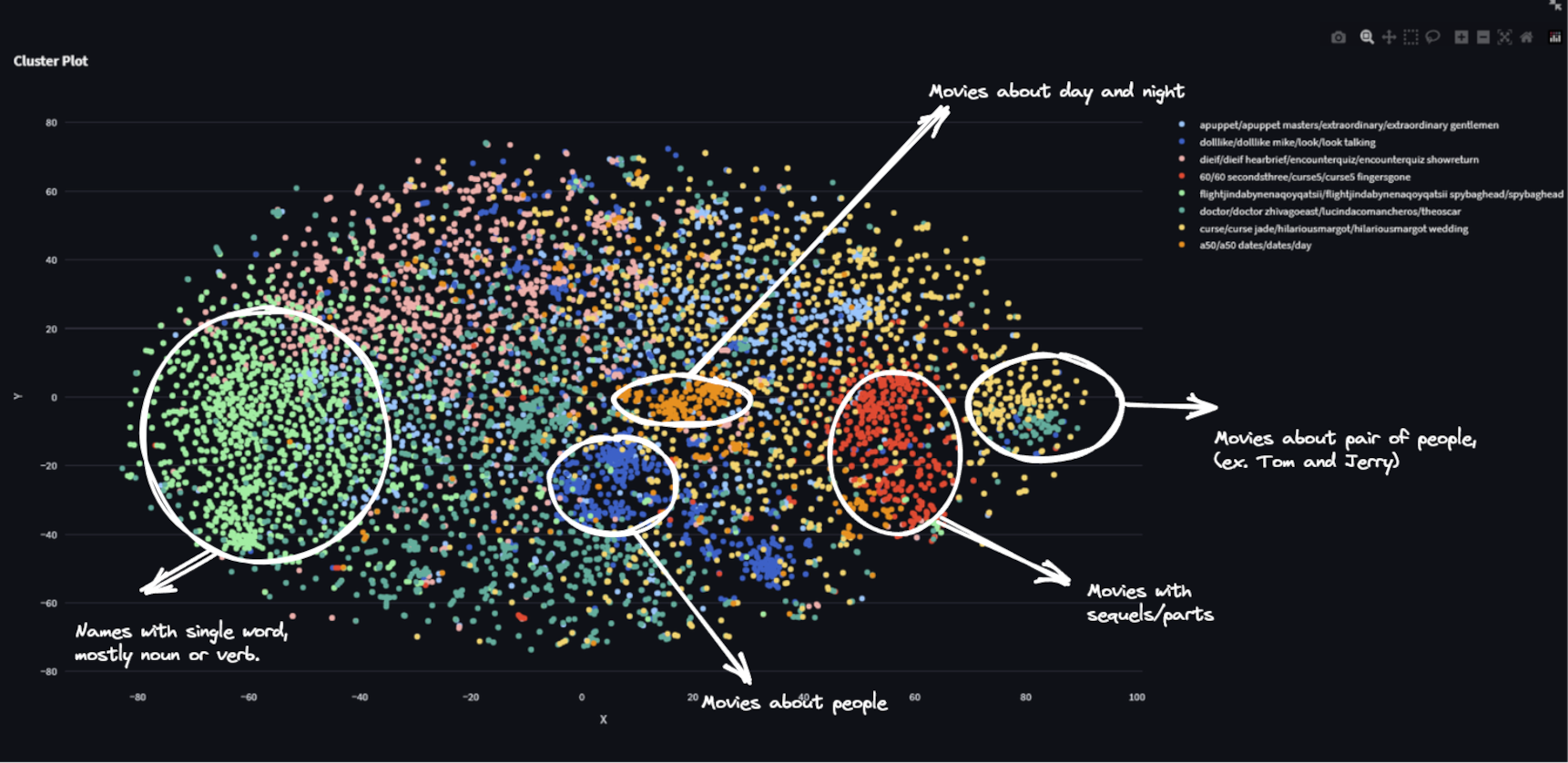
ClustrLab2k13 is a robust Python-based application designed for semantic text clustering, utilizing Streamlit. The tool harnesses the power of Google’s Universal Sentence Encoder in combination with OpenTSNE, a highly efficient t-SNE implementation. It seamlessly processes both plain text files and CSV files with a single text column. When dealing with plain text files, it employs sentence embedding similarity to group sentences into ‘pseudo paragraphs,’ offering a convenient way to structure the data. Alternatively, users can choose the CSV mode to avoid this grouping. Here is a short video of the tool in action
Video of the tool in action.
Moreover, the tool provides the ability to download all data, including text, embeddings, and TSNE output. It was inspired and built upon code from my previous repository, ‘Feed Visualizer‘. For user convenience, contextual help is available for each option, eliminating the need for a detailed manual. Here is link to code of the tool: https://github.com/code2k13/ClustrLab2k13
To install tool you will need Linux, 8-16 GB RAM,Python 3.11.1. Install all dependencies using requirements.txt. I have not been able to successfully run it on M1 Macs and Windows due to issue with tensorflow-text package.
To run the application run the below commands:
git clone https://github.com/code2k13/ClustrLab2k13 |
Furthermore, the tool offers an alternative to Google’s ‘Universal Sentence Transformer’ by providing an ‘use zero-shot embedding’ option, which leverages Huggingface’s zero-shot classification to generate embeddings based on assigned labels. For instance, if you label sentences as “positive, negative, neutral,” the resulting embeddings might look like “0.3, 0.4, 0.3.” However, it is important to exercise caution while experimenting with this option, especially without a GPU, as it has not been extensively tested on large datasets.



