
One of my long-standing interests has been making things smaller, faster, and more efficient — whether it’s embedded systems or TinyML (Tiny Machine Learning). This philosophy naturally extends to language models, where a growing movement is exploring Small Language Models (SLMs) as an efficient alternative to Large Language Models (LLMs).
Unlike LLMs that require massive infrastructure and often rely on cloud inference, SLMs can be fine-tuned for specific, well-defined tasks and deployed locally — saving cost, latency, and enhancing data privacy.
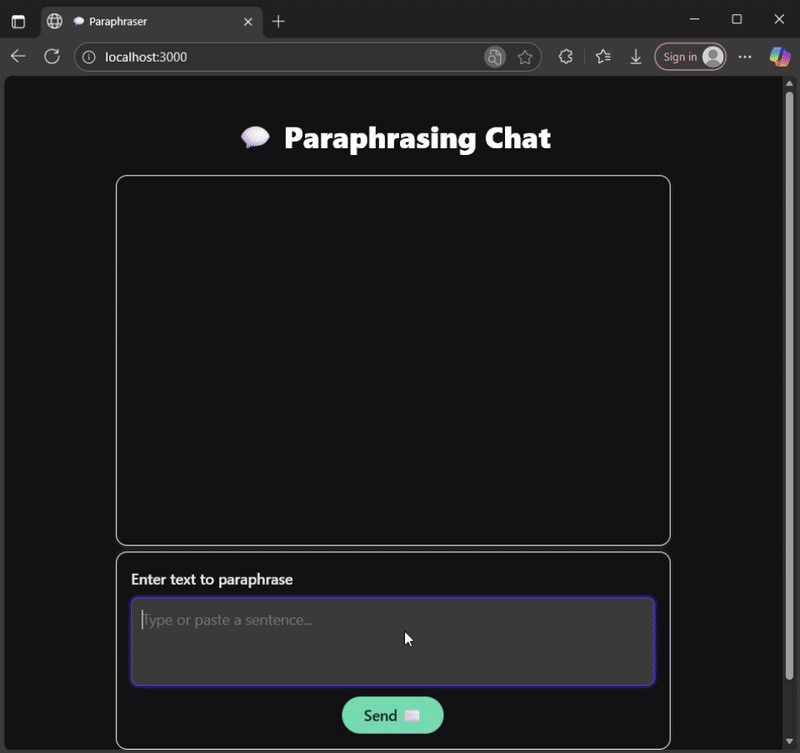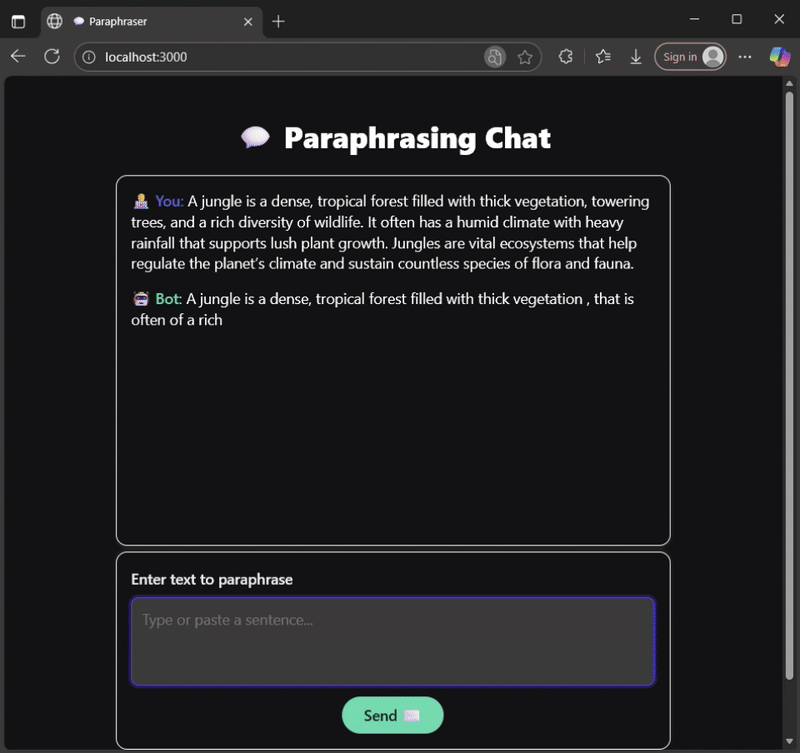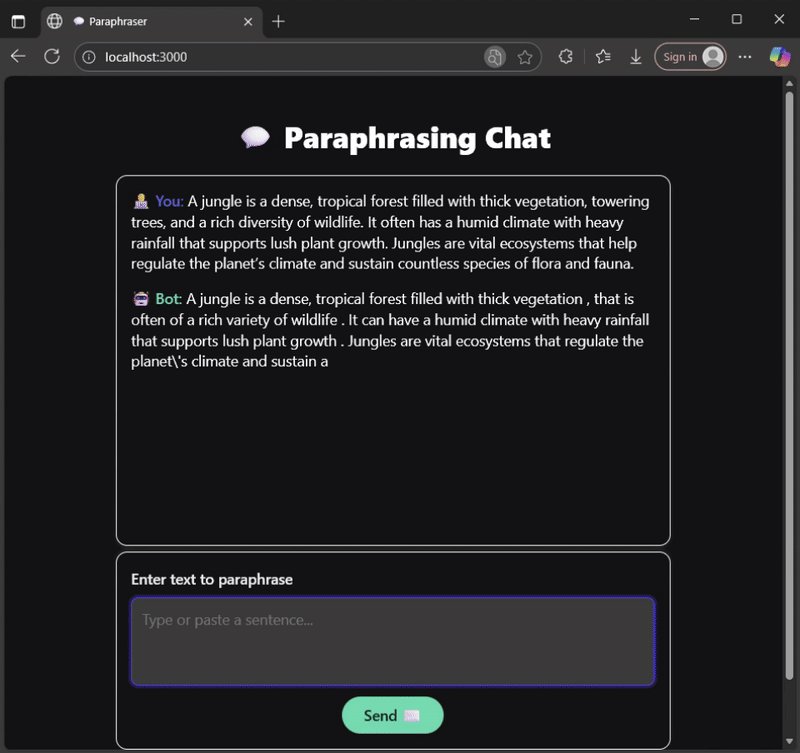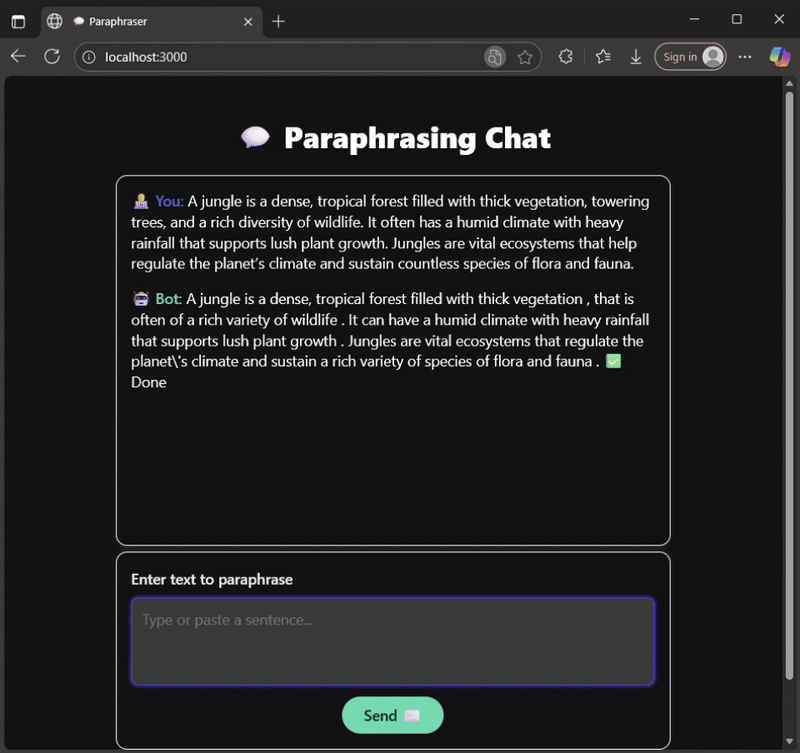

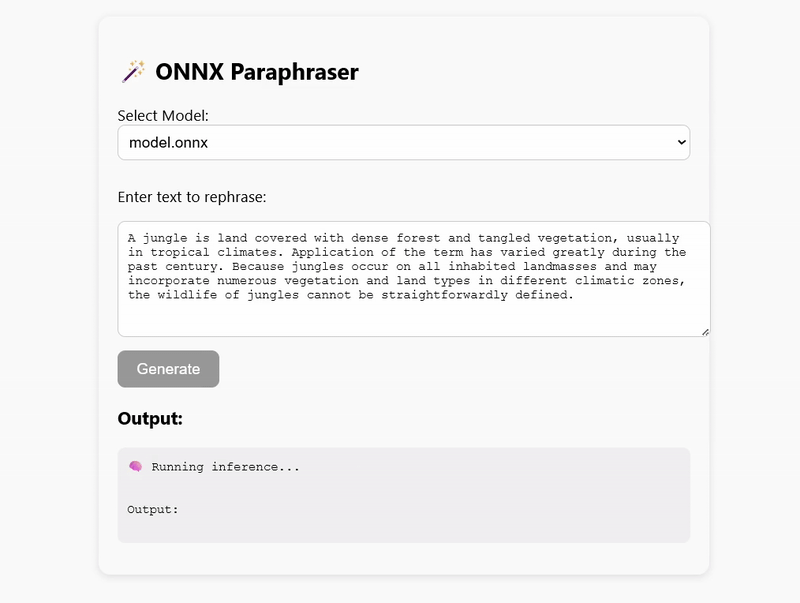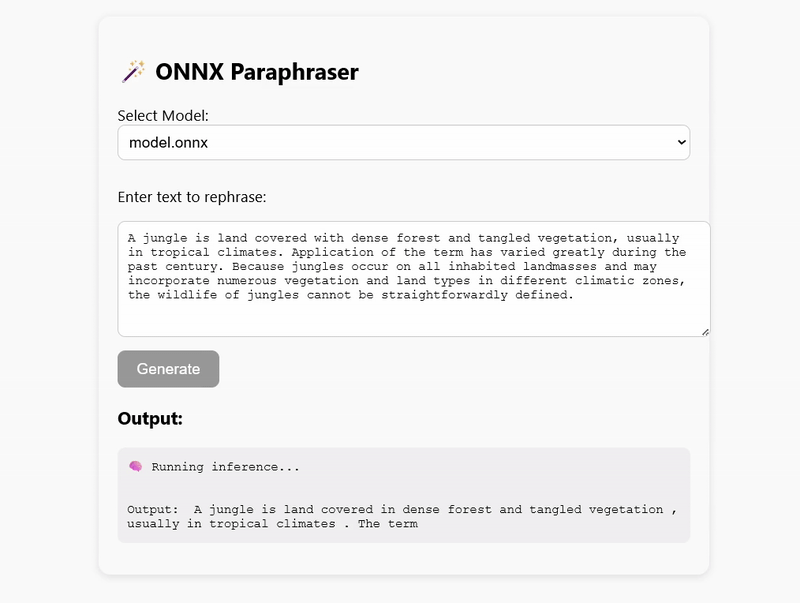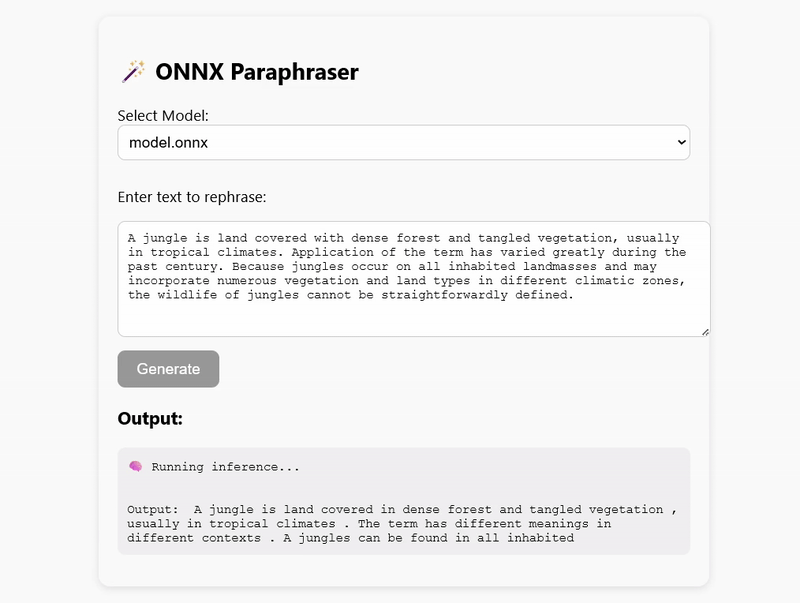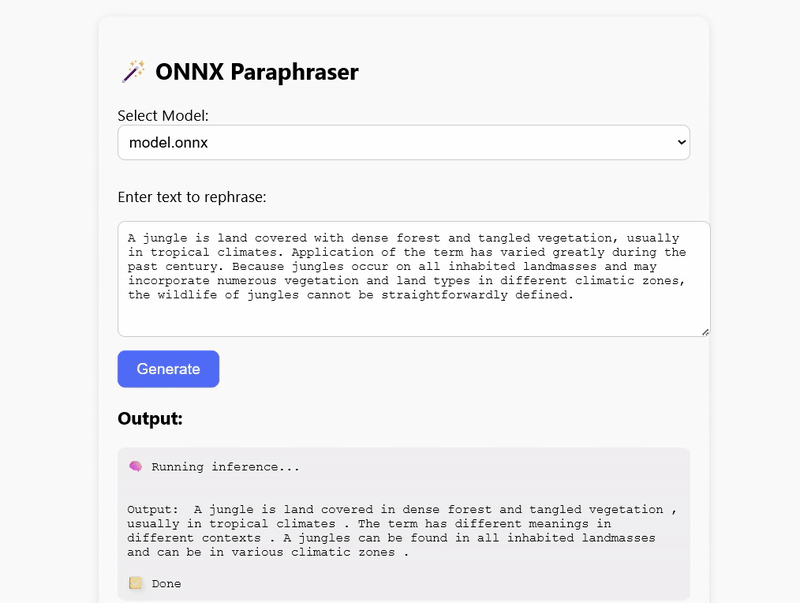

Why a Small Language Model?
For this experiment, I selected HuggingFaceTB/SmolLM-135M, a transformer-based model with 135 million parameters (not characters).
This size strikes a balance — it’s compact (≈250 MB) yet powerful enough for domain-specific fine-tuning.
Another reason is behavioral: the base model tends to hallucinate (generate inaccurate or irrelevant text), which makes it an ideal candidate for LoRA fine-tuning — a lightweight training approach that adds small, task-specific layers on top of the frozen base model.
Fine-tuning a model of this size takes about 9 hours for three epochs on a standard GPU, making it suitable for rapid experimentation and iteration.
Fine-Tuning Workflow
The fine-tuning process is documented in my Kaggle notebook:
👉 Fine-tuning SmolLM-135M for Paraphrasing Tasks
Here’s the workflow:
- Dataset: Instead of the commonly used Quora Q&A dataset, I chose the PAWS dataset (Paraphrase Adversaries from Word Scrambling) because it contains plain declarative sentences, ideal for paraphrasing tasks.
- Data Augmentation: To enhance learning, I reversed the sentence pairs, effectively doubling the dataset.
- Training Objective: Teach the model to rewrite text with different wording while preserving meaning.
- Special Tokens: Added <|OUTPUT_START|> and <|OUTPUT_END|> markers around the target text during training. This significantly reduced hallucinations by making output boundaries explicit.
- LoRA Fine-Tuning: Applied Low-Rank Adaptation (LoRA), which updates only a small subset of parameters, reducing compute and memory costs.
The result is a set of LoRA adapter weights, available here:
📦 LoRA Weights Dataset on Kaggle
Merging and Exporting the Model
A second Kaggle notebook merges the LoRA weights with the base SmolLM model, producing a fully fine-tuned model ready for deployment:
👉 SmolLM-360 LoRA ONNX Inference
This notebook performs two key tasks:
- Merges LoRA adapters into the base model.
- Exports the final model to ONNX (Open Neural Network Exchange) format, optionally quantizing it (reducing precision to lower memory usage).
Why ONNX?
The ONNX format allows a trained model to run on virtually any platform — Python, Node.js, C++, or directly in a web browser — through the ONNX Runtime library.
This portability removes dependency on heavy deep learning frameworks like PyTorch or TensorFlow, making the deployment lightweight, flexible, and accessible even in constrained environments.
Deployment: Node.js vs Browser
My GitHub repository contains working examples of how to run inference in both Node.js and the browser using WebAssembly (WASM):
🔗 GitHub Repository – SmolLM ONNX Paraphraser
Key observations:
Node.js runtime performs inference about 2× faster than the browser version and uses roughly 900 MB of RAM for unquantized models.
Browser (WASM) execution, while slower, provides complete privacy since all computation happens locally with no data leaving the device.
It uses approximately 2 GB of memory, reflecting current WASM overhead.
- Quantized models (8-bit or 9-bit) did not yield significant benefits in performance or memory usage for this setup, although this may improve with future runtime optimizations.
The Broader Trend: Private AI in the Browser
The idea of running AI models entirely within the browser—without any external API calls—represents the future of privacy-preserving AI.
Recent developments like Google’s Gemini Nano (integrated directly into Chrome) demonstrate this trend toward on-device intelligence.
As browsers begin to include dedicated AI acceleration APIs, running SLMs locally will become commonplace for productivity, summarization, translation, and creative writing tasks — all without connecting to a server.
Summary
- This workflow provides a reproducible path to:
- Fine-tune a small transformer model for a domain-specific NLP task (here: paraphrasing).
- Merge and export it to ONNX format for maximum portability.
- Deploy it securely inside a browser or any ONNX-compatible runtime, enabling local, private inference.
- While the performance is not yet on par with large cloud models, the approach offers speed, cost-efficiency, and privacy — key pillars for enterprise-grade AI adoption at scale.
Citation
@misc{allal2024SmolLM, |



